> Semantic segmentation
어떤 이미지가 있을 때 어떤 픽셀마다 어떤 라벨에 속하는지 분류하는것.
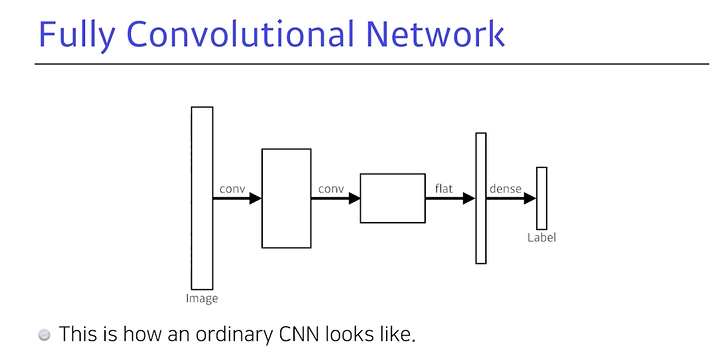
.
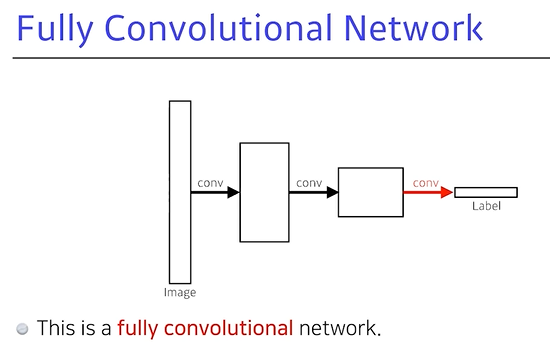
Fully Convolutional Network란 덴스 레이어를없애고 싶은거.
우리가 아웃풋이 1000단짜리가 나오면 1000단짜리가 아니라 convolution layer로 바꾸자는 거임.
이 덴스 레이어를 없애는 과정을 콘볼루션라이제이션 이라 부르고 이거의 가장 큰 장점은 덴스 레이어가 없어진것.
궁극적으로 보면 인풋과 아웃풋이 동일함.

왜 이런 짓을 할까?
- Fully Convolutional Network는 인풋에 상관없이 돌아간다. 아웃풋이 커지게 되면 그에따라 뒷단 네트워크가 커지게 된다.
원래는 분류만 했던것이 이미지가 커지면 히트맵이 나올 수있음.!!
Transforming fully connected layers into convolution layers enables a classification net to output a heap map.
While FCN can run with inputs of any size, the output dimensions are typically reduced by subsampling.
So we need a way to connect the coarse output to the dense pixels.
FCN은 모든 크기의 입력으로 실행할 수 있지만, 출력 치수는 일반적으로 하위 샘플링에 의해 감소됩니다.
그래서 우리는 조잡한 출력물을 조밀한 픽셀에 연결하는 방법이 필요하다.
-> 늘리는 방법 1. Deconvolution ( conv transpose )
직관적으로는 역 convolution이라고 생각하면 이해하기 좋음.
스페셜 디멘션을 키워주는 역할
사실상 복원은 불가능하긴함 ex) 10은 2+8, 7+3 ... 여러개기 때문!
Deconvolution 은 패딩을 많이줘서 원하는 걸로 복원.
즉 결과론적으로 이야기하면
Deconvolution 은 convolution의 엄밀한 역은 아니지만 파라미터 숫자와 네트워크 입력과 출력으로 볼땐 동일해진다.
> Detection
>> R-CNN
R-CNN (1) takes an input image, (2) extracts around 2,000 region proposals (using Selective search),
(3) compute features for each proposal (using AlexNet), and then
(4) classifies with linear SVMs
( 번역 :
(1) 입력 이미지를 촬영합니다,
(2) 약 2,000개의 지역 제안서를 추출합니다(선택 검색 사용),
(3) 각 제안에 대한 기능을 계산합니다(AlexNet 사용)
(4) 선형 SVM으로 분류
)
약간 노가다성임 모든 이미지에서 2000지역나누고 ... 막 분류하고..
>> SPPNet
R-CNN의 문제는 이미지 안에서 바운딩 박스를 2000개 이미지 다 통과해야하는거임!
- In R-CNN, the number of crop/warp is usually over 2,000 meaning that CNN must run more than 2,000 times (59s/image on CPU).
- However, in SPPNet, CNN runs once.
한번 돌린후 얻어진 Feature 맵을 추출해서 거기서 돌림
즉 한번 돌려서 이미지 부분을 추출해서 돌리는거
>> Fast R-CNN
1. Takes an input and a set of bounding boxes.
2. Generated convolutional feature map
3. For each region, get a fixed length feature from ROI pooling
4. Two outputs: class and bounding-box regressor.
( 1. 입력 및 경계 상자 집합을 사용합니다.
2. 생성된 컨볼루션 피쳐 맵
3. 각 영역에 대해 ROI 풀링을 통해 고정 길이 기능 제공
4. 두 가지 출력: 클래스와 경계 상자 회귀기. )
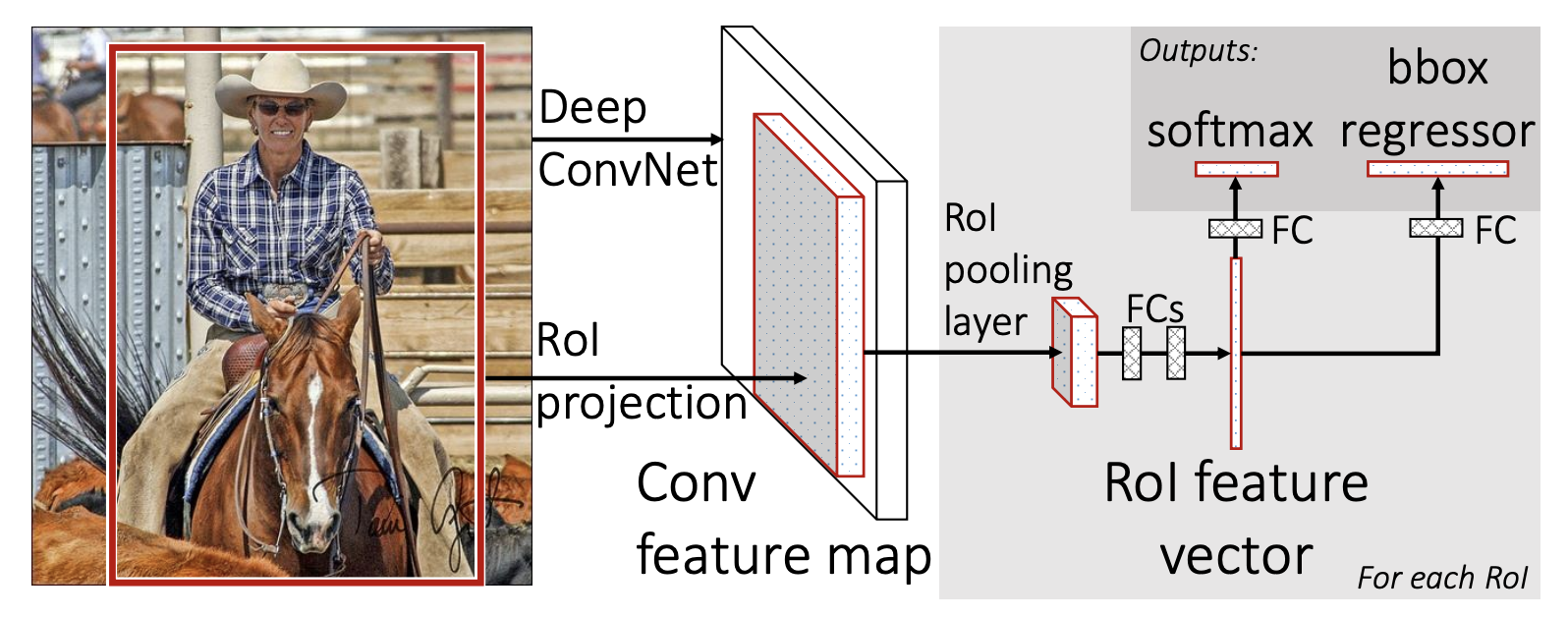
기본 컨셉은 SPPNet 과 매우 비슷한데, 뒷단에 뉴럴 네트워크를 통해서
>> Faster R-CNN
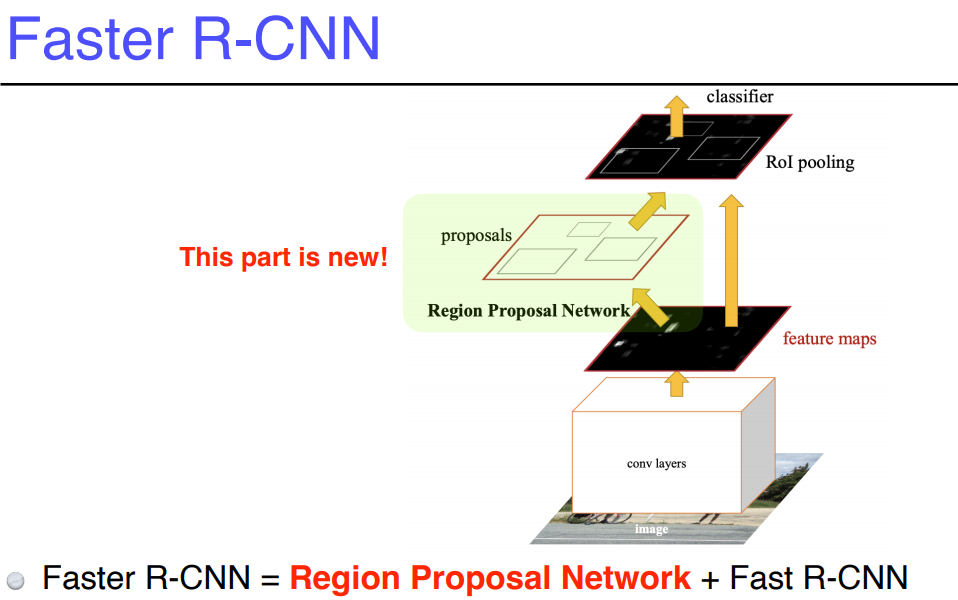
RPN이 추간된건데,
이 RPN이란 이미지가 있으면 이 이미지의 특정 영역이 (path) 바운딩 박스로서의 의미가 있을지 없을지 찾아주는 거.
이 안에 물체가 무엇인지는 뒷단 네트워크가 해주지만, 이 안에 물체가 있을지 파악하는게 RPN
이를 위해 필요한 것이 Anchor boxes ( detection boxes with predefined sizes )
Anchor boxes 란 미리 정해놓은 바운딩 박스의 크기.( 찾을 객체의 크기 )
대충 이 안에 어떤 크기의 물체들이 있을 것 같다라는걸 미리 알고있는거임.
RPN도 풀리 컨버션 네트워크임.
>> YOLO ( v1 기준 설명. 실제로 v2는 바운딩박스 사이즈 미리정하고.. 얼만큼 변해야할지 찾고.. 조금 추가된게 있기도 )
Faster R-CNN보다 훠얼씬더 빠르다.
지역을 나눠서 그 지역에서 분류하는게 아니라
YOLO는 그냥 이미지 한장에서 바로 아웃풋이나옴.,
( You only look one = YOLO )
It simultaneously predicts multiple bounding boxes and class probabilities.
여러 경계 상자와 클래스 확률을 동시에 예측합니다.
No explicit bounding box sampling (compared with Faster R-CNN)
명시적 경계 상자 샘플링 없음(Faster R-CNN과 비교)
Faster R-CNN는 바운딩 박스를 찾는 region proposals network 가 있었고 거기서 나오는 바운딩 박스를 따로 분류하였음. 그러나 YOLO는 한번에 분류
그래서 region proposals 스텝이 없기에 속도가 빠름!!

- 이미지가 들어오면 SxS grid로 나누게 됩니다.
(물체의 중심이 그리드 셀에 떨어지면, 그 그리드 셀이 감지를 담당한다.)

- 각각의 셀은 B개의 바운딩 박스를 예측하게됩니다.
- 각각의 바운딩 박스는 다음을 예측하는디
- box refinement (x / y / w / h)
- confidence (of objectness) - 이 박스가 쓸모가 있는지
- 그와 동시에 각각의 셀들은 이 중점에있는 오브젝트가 C 클래스 일지 확률 예측함 ( 아래있는 사진 )
원래라면 바운딩 박스 찾고 거기서 나온걸 따로 네트워크 돌려서 Class를 찾았다면 이걸 동시에 하는거임.
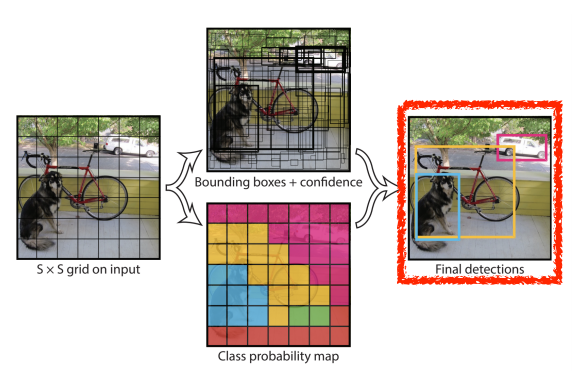
- 이 두개의 정보를 취합하면 이 박스가 어떤 클래스인지 나오게 되는거임
- In total, it becomes a tensor with SxSx(B*5+C) size.
( 텐서로 보면 S x S x (B{바운딩박스개수} * 5{박스에 대한 프로퍼티 쓸지말} + C(클래스))
SxS: Number of cells of the grid
B*5: B bounding boxes with offsets
(x,y,w,h) and confidence
C: Number of classes
YOLO는 faster R-CNN에 비해서 바운딩박스를 찾는것과 동시에 클래스를 찾는것도 같이 하기때문에 매우 빠름.
'공부 정리 ( 강의 ) > 딥러닝 기초 다지기' 카테고리의 다른 글
| 4.2. Sequential Models - Transformer (0) | 2023.01.07 |
|---|---|
| 4.1. Sequential Models - RNN (1) | 2023.01.07 |
| 3.2. Modern CNN - 1x1 convolution의 중요성 (0) | 2023.01.07 |
| 3.1. CNN - Convolution은 무엇인가? (0) | 2023.01.07 |
| 2.3. Regularization - 오버피팅 막기 # 나중필요 (0) | 2023.01.07 |