
1. Adaptive RAG
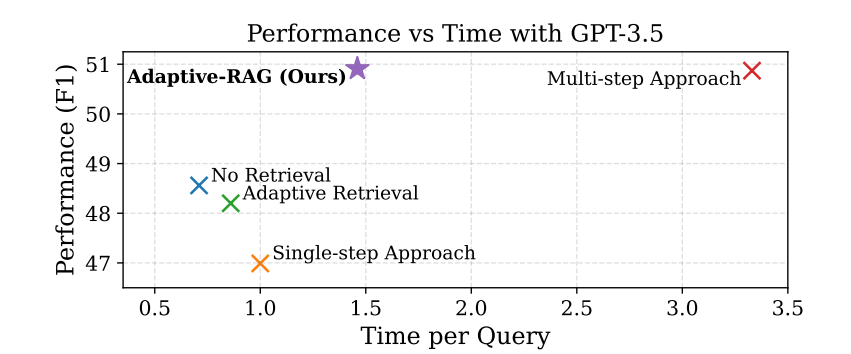
질문의 복잡도, 난이도에 따라서 가장 적합한 검색 및 생성 전략을 동적으로 선택하는 방법
단순한 질문, 좀 가벼운 LLM 입장에서 답변하기 쉬운 그런 단순한 질문 같은 경우 단순한 구조의 RAG 체인을 사용.
복잡한 질문, 좀 풀어내기 어려운 질문에 대해서는 반복적으로 여러번 RAG 전략을 사용하는 기법.
문제의 난이도에 따라서 레그 전략을 다르게 가져가는 방법.
Adaptive RAG 작동 방식
1. 사용자 질문의 복잡성 수준을 분석
2. 분석 결과에 따라 가장 적합한 처리 전략을 선택
- 단순 질문 : 기본 LLM 또는 단순 검색
- 중간 복잡성 : 단일 단계 검색 증강 LLM 사용
- 복잡한 질문 : 여러 단계의 검색과 추론을 수행
3. 선택된 전략에 따라 질문을 처리하고 응답 생성.
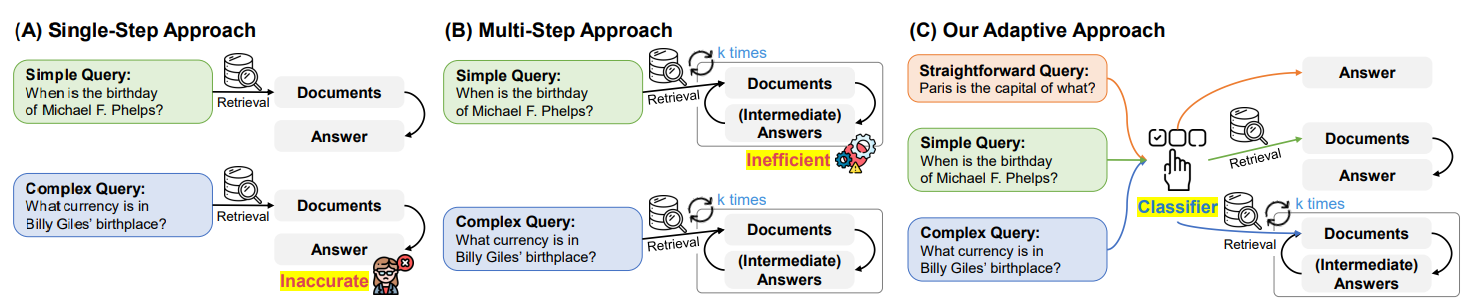
( A ) Single-Step Approach :
심플 쿼리, 풀어내기 쉬운 질문에 대해서 문서를 검색하고, 검색된 문서에 기반해서 바로 답변을 해주는 방식으로 작동.
복잡한 쿼리에 대해서는 검색을 한번 해서 한번 검색된 문서로 답변을 생성했을 경우 즉 저희가 일반적으로 사용하는 RAG 기법을 싱글 스텝으로 이렇게 적용했을 경우에는 답변의 품질이 기대했던 것 만큼 잘 안나오는 그런 문제가 있음.
그래서 이 복잡한 문제를 풀어낼 때는
( B ) Multi-Step Approach같이 검색을 여러번 수행하고 검색 기법들도 굉장히 여러가지 검색 도구를 사용한다거나 하이브리드 검색을 한다거나 그래서 검색을 여러 번 수행을 하고 다양한 검색을 통해서 검색한 문서 기반으로 여러개의 중간 답변들을 생성을 하고 이 중간 답변들을 가지고 최종 답변을 생성하는 형태로 풀어냄.
하지만 이 Multi-Step Approach로 RAG전략을 고정하게 되면 복잡한 문제를 풀어내는 데는 효과적이지만, 이런 싱글 쿼리 단순한 문제를 풀어낼 때는 이걸 여러번 반복하게 되면 이 자체가 굉장히 비효율적인 그런 접근법이 됨.
( C ) Our Adaptive Approach :
그래서 이 Adaptive RAG 논문에서는 Adaptive approach로 직접적인 질문에 대해서는 바로 LLM이 별도의 rag를 사용하지 않고 바로 답변을 하게 되고,
이 중간에 분류하는 그런 로직을 추가를 해서 직접적인 좀 단순한 llm이 바로 답변할 수 있는 것들은 바로 답변을 생성하게 하고
RAG가 필요한 쿼리일 경우 해당 쿼리가 심플, 단순 쿼리인지 복잡한 쿼리인지 문제의 복잡도 및 난이도를 먼저 분석하고 그 분석 결과를 토대로 해서
심플 쿼리에 대해서는 검색을 한번 수행해서 RAG 답변을 생성하는 그런 흐름을 진행하고 컴플렉스 쿼리에 대해서는 RAG를 여러번 반복적으로 수행하는 그런 방법을 선택하게 하는 기법을 이야기합니다.

참고 :
- https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_adaptive_rag/
- https://arxiv.org/abs/2403.14403
2. Self-RAG
- Self-RAG는 기존의 RAG 모델에 자기 반영(self-reflection) 능력을 추가한 확장 모델
- 정보 검색, 생성 그리고 자체 평가를 통합하여 더 정확하고 관련성 높은 응답을 생성하는 것을 목표
Self-RAG 작동 방식
1. 초기 쿼리 처리 : 사용자의 질문을 받아 관련 정보를 검색
2. 초기 응답 생성 : 검색된 정보를 바탕으로 첫 번째 응답 생성
3. 자기 평가 : 생성된 응답의 품질, 관련성, 정확성을 평가
4. 개선 결정 : 추가 정보 검색 또는 응답 재생성을 결정
5. 반복 : 만족스러운 결과를 얻을 때까지 이전 단계를 반복

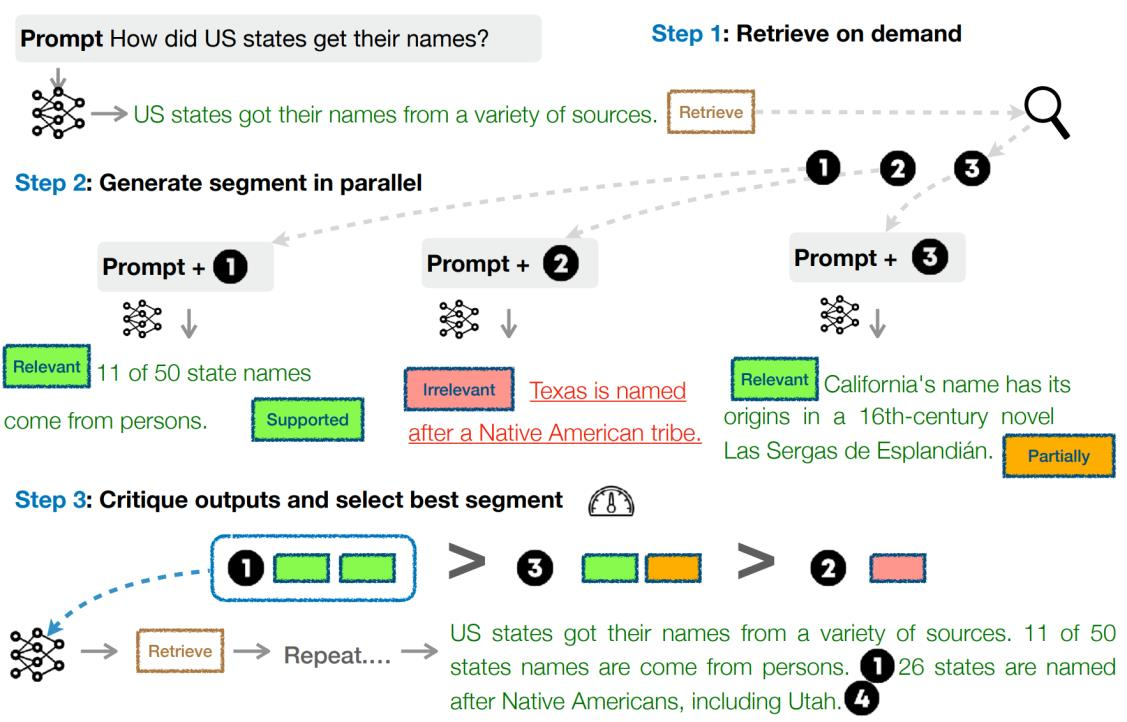

참고 :
- https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_self_rag/?h=self
- https://arxiv.org/abs/2310.11511
3. Corrective RAG (CRAG)
- CRAG는 기존 RAG 시스템을 개선하여 검색된 정보의 품질과 관련성을 향상시키는 접근 방식
- 문서 관련성 평가, 지식 정제, 필요 시 외부 지식 탐색, 그리고 정제된 지식을 바탕으로 한 답변 생성
위의 1. Adaptive RAG , 2. Self RAG와 비슷한 방식이 적용된 RAG 기법.
두 RAG 기법과의 차이는 지식정제라는 부분이 추가되어있음. 기본적으로 RAG 시스템에서는 사전에 정리해둔 어떤 벡터 저장소, 내부 지식 베이스에서 정보 검색을 하는데, 그 정보 검색이 충분하지 않은 경우에 재검색을 할 수도 있지만,
해당 CRAG에서는 검색된 문서가 가지고 있는 정보를 정제하는 과정이 추가되어 있고 필요하다면 외부 지식 즉 내부적으로 갖고있는 저장소 지식 뿐 아니라 웹검색을 통해서 외부에 있는 지식을 탐색해서 기존의 RAG가 갖고있던 한계점, 최신 정보에 대해서 답변을 못한다거나 하는 한계점을 극복하고자함.
문서 안에서 갖고있는 어떤 특정한 개념에 대해서도 외부에 있는 믿을만한 소스로부터 정보를 가져와서 외부 지식을 결합해서 답변할 수 있는 형태로 최종 답변을 생성해보자라는 아이디어가 CRAG.
CRAG 작동 방식
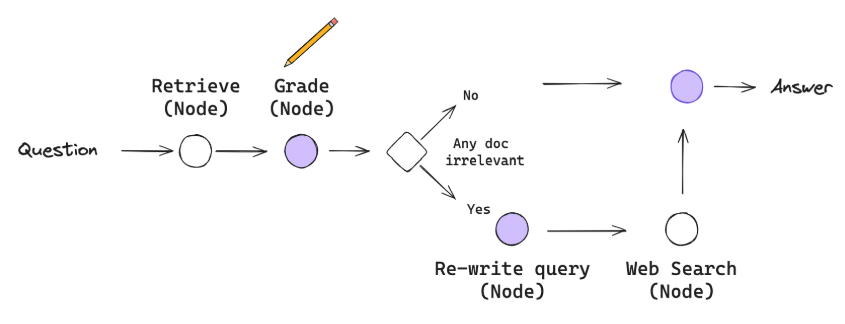
1. 문서 관련성 평가: Retrieval 문서에 대한 평가
2. 지식 정제: Retrieval 문서 중에서 중요한 정보만 추출
3. 지식 검색: Retrieval 문서가 부족할 경우, 외부 지식(웹)을 탐색
4. 답변 생성: 정제 지식을 활용하여 답변 생성
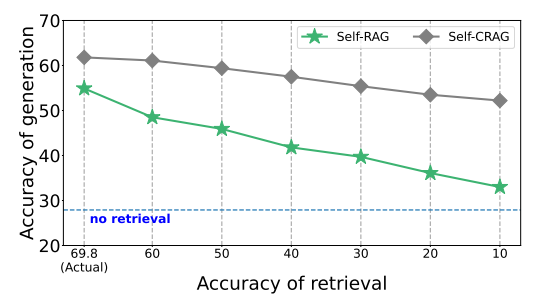
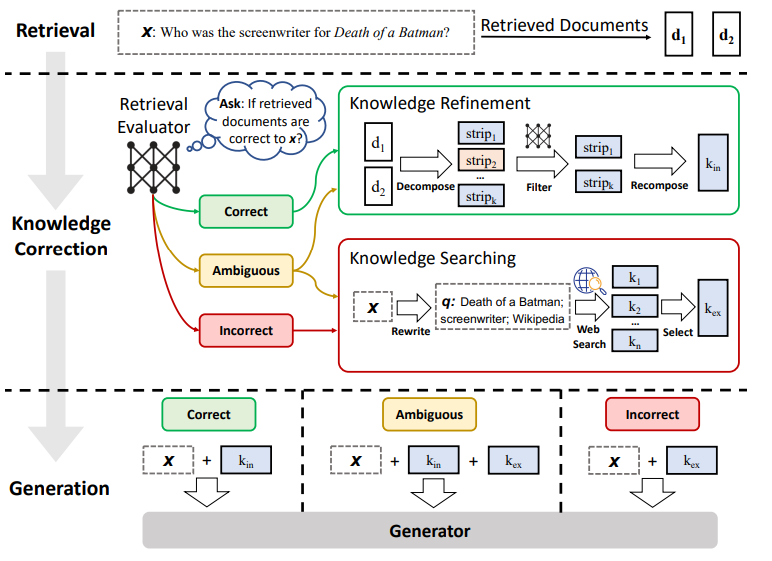
Retrieval 검색을 수행하고 Knowledge Correction 단계 지식을 수정하는 단계가 추가되는데 검색된 문서에 대해서 평가작업을 거칩니다.
문서 관련성 평가를 먼저 거쳐서 이 부분에서 Correct 그리고 Incorrect, Ambiguous로 관령성을 나눕니다.
관련성이 있는 문서( Correct )와 애매한 문서들( Ambiguous )의 경우에는 지식 정제 과정을 거쳐서 최종적으로 컨텍스트,
즉 LLM 모델이 참조하는 컨텍스트를 조금 더 정제해줍니다.
문서가 굉장히 길을 수도 있고 그 중에 실제 질문과 관련되어 있는 부분들만 추출해서 제공해 준다면, LLM 모델의 최종 답변을 생성을 할 때 조금 더 중요한 정보에 집중할 수 있기 때문에 컨텍스트 자체를 조금 정제해서 개선해 보는 아이디어가 적용이 되어 있습니다.
그리고 문서 관련성 평가 결과가 애매하거나( Ambiguous ) 또는 부적절한 경우( Incorrect )에는 Knowledge Searching 단계 즉 웹 검색을 통해서 외부 지식을 추가적으로 탐색해서 컨텍스트에 문서를 제공해주는 이 두가지 아이디어가 들어가 있습니다.
내부지식도 Refine을 통해서 정제를 해주고 필요하다면 내부 지식이 갖고있는 한계를 좀 극복하기 위해서 외부 지식까지 활용하는 아이디어가 들어가 있습니다. 그렇게 해서 이제 검색된 문서를 가지고 또는 정제된 문서를 가지고 최종적으로 생성을 하게 됩니다.
참고 :